|
本人博客开始迁移,博客整个架构自己搭建及编码 http://www.cookqq.com writeable接口对java基本类型提供了封装,short和char除外。所有的封装包含get()和set()两个方法用于读取和设置值。
现在看一下IntWritable的源码 /**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.io;
import java.io.*;
/** A WritableComparable for ints. */
public class IntWritable implements WritableComparable {
private int value;
public IntWritable() {}
public IntWritable(int value) { set(value); }
/** Set the value of this IntWritable. */
public void set(int value) { this.value = value; }
/** Return the value of this IntWritable. */
public int get() { return value; }
public void readFields(DataInput in) throws IOException {
value = in.readInt();
}
public void write(DataOutput out) throws IOException {
out.writeInt(value);
}
/** Returns true iff <code>o</code> is a IntWritable with the same value. */
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
return false;
IntWritable other = (IntWritable)o;
return this.value == other.value;
}
public int hashCode() {
return value;
}
/** Compares two IntWritables. */
public int compareTo(Object o) {
int thisValue = this.value;
int thatValue = ((IntWritable)o).value;
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
public String toString() {
return Integer.toString(value);
}
/** A Comparator optimized for IntWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(IntWritable.class);
}
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int thisValue = readInt(b1, s1);
int thatValue = readInt(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
}
static { // register this comparator
WritableComparator.define(IntWritable.class, new Comparator());
}
}
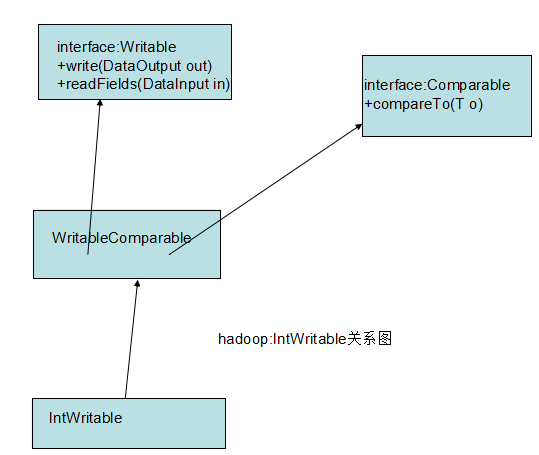
IntWritable的关系图:
(1)IntWritable实现了接口Writable的2个方法:一个用于将其状态写入二进制格式的DataOutput流,另一个用于从二进制格式的DataInput流读取其态 write和readFields分别实现了把对象序列化和反序列化的功能,是Writable接口定义的两个方法 (2)IntWritable声明了变量value,并且实现了set,get方法 (3)声明内部类Comparator,并且实现WritableComparator接口中比较未被序列化的对象方法 (4)注册comparator Hadoop自带一系列有用的Writable实现,可以满足绝大多数用途。但有时,我们需要编写自己的自定义实现。通过自定义Writable,我们能够完全控制二进制表示和排序顺序。Writable是MapReduce数据路径的核心,所以调整二进制表示对其性能有显著影响。现有的Hadoop Writable应用已得到很好的优化,但为了对付更复杂的结构,最好创建一个新的Writable类型,而不是使用已有的类型。 为了演示如何创建一个自定义Writable,我们编写了一个表示一对字符串的实现,名为TextPair importjava.io.*; import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<textpair> {
private Text first;
private Text second;
public TextPair() {
set(newText(),newText());
}
public TextPair(String first, String second) {
set(newText(first),newText(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out)throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in)throwsIOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() *163+ second.hashCode();
}
@Override
public boolean equals(Object o) {
if(o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public String toString() {
return first +"\t"+ second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if(cmp !=0) {
return cmp;
}
return second.compareTo(tp.second);
}
}
此实现的第一部分直观易懂:有两个Text实例变量(first和second)和相关的构造函数、get方法和set方法。所有的Writable实现都必须有一个默认的构造函数,以便MapReduce框架能够对它们进行实例化,进而调用readFields()方法来填充它们的字段。 Writable实例是易变的、经常重用的,所以我们应该尽量避免在write()或readFields()方法中分配对象。 通过委托给每个Text对象本身,TextPair的write()方法依次序列化输出流中的每一个Text对象。同样,也通过委托给Text对象本身,readFields()反序列化输人流中的字节。DataOutput和DataInput接口有丰富的整套方法用于序列化和反序列化Java基本类型,所以在一般情况下,我们能够完全控制Writable对象的数据传输格式。 正如为Java写的任意值对象一样,我们会重写java.lang.Object的hashCode()方法,equals()方法和toString()方法。HashPartitioner使用hashCode()方法来选择reduce分区,所以应该确保写一个好的哈希函数来确保reduce函数的分区在大小上是相当的。 TextPair是WritableComparable的实现,所以它提供了compareTo()方法的实现,加入我们希望的顺序:它通过一个一个String逐个排序。请注意,TextPair不同于前面的TextArrayWritable类(除了它可以存储Text对象数之外),因为TextArrayWritable只是一个Writable,而不是WritableComparable。 实现一个快速的RawComparator 上例中所示代码能够有效工作,但还可以进一步优化。正如前面所述,在MapReduce中,TextPair被用作键时,它必须被反序列化为要调用的compareTo()方法的对象。是否可以通过查看其序列化表示的方式来比较两个TextPair对象。 事实证明,我们可以这样做,因为TextPair由两个Text对象连接而成,二进制Text对象表示是一个可变长度的整型,包含UTF-8表示的字符串中的字节数,后跟UTF-8字节本身。关键在于读取开始的长度。从而得知第一个Text对象的字节表示有多长,然后可以委托Text对象的RawComparator,然后利用第一或者第二个字符串的偏移量来调用它。下面例子给出了具体方法(注意,该代码嵌套在TextPair类中)。 public static class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR =new Text.Comparator();
public Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1,int s1,int l1,
byte[] b2,int s2,int l2) {
try{
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if(cmp != 0) {
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1,
b2, s2 + firstL2, l2 - firstL2);
}catch(IOException e) {
throw new IllegalArgumentException(e);
}
}
}
static{
WritableComparator.define(TextPair.class,newComparator());
}
事实上,我们一般都是继承WritableComparator,而不是直接实现RawComparator,因为它提供了一些便利的方法和默认实现。这段代码的精妙之处在于计算firstL1和firstL2,每个字节流中第一个Text字段的长度。每个都由可变长度的整型(由WritableUtils的decodeVIntSize()返回)和它的编码值(由readVInt()返问)组成。 静态代码块注册原始的comparator以便MapReduce每次看到TextPair类,就知道使用原始comparator作为其默认comparator。 自定义comparator 从TextPair可知,编写原始的cornparator比较费力,因为必须处理字节级别的细节。如果需要编写自己的实现,org.apache.hadoop.io包中Writable的某些前瞻性实现值得研究研究。WritableUtils的有效方法也比较非常方便。 如果可能,还应把自定义comparator写为RawComparators。这些comparator实现的排序顺序不同于默认comparator定义的自然排序顺序。下面的例子显示了TextPair的comparator,称为First Comparator。只考虑了一对Text对象中的第一个字符串。请注意,我们重写了compare()方法使其使用对象进行比较,所以两个compare()方法的语义是相同的。 public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR =newText.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1,ints1,intl1,
byte[] b2,ints2,intl2) {
try{
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
}catch(IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if(a instanceof TextPair && b instanceof TextPair) {
return((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}
参考:《hadoop权威指南》 |
 Writable的Java基本类封装
Writable的Java基本类封装