|
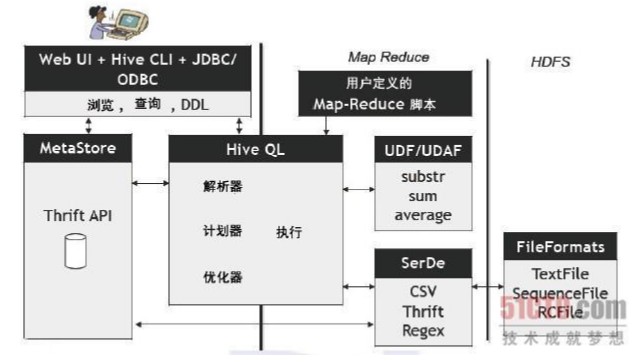
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。 Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。 Hive 可以看成是从SQL到Map-Reduce的 映射器hive的组件和体系架构: hive web接口启动:./hive --service hwi 默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会话,则需要一个独立的元数据库,我们使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。 Hive安装 内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接 本地独立模式:在本地安装Mysql,把元数据放到Mysql内 远程模式:元数据放置在远程的Mysql数据库。 Hive的数据放在哪儿? 数据在HDFS的warehouse目录下,一个表对应一个子目录。 本地的/tmp目录存放日志和执行计划 hive的表分为两种,内表和外表。 使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
|